TLDR¶
![]()
simplEvals¶
- In production
- In real time
- In front of the client
optimising performance, cost and latency - ROI!
Set business success criteria and ROI - SMART
Evaluate to measure increase in success and consequent ROI
Use meaningful labels rather than numeric scores
Two decoupled parts - observability and evaluation
Observability¶
- Observability by tracing/logging out data.
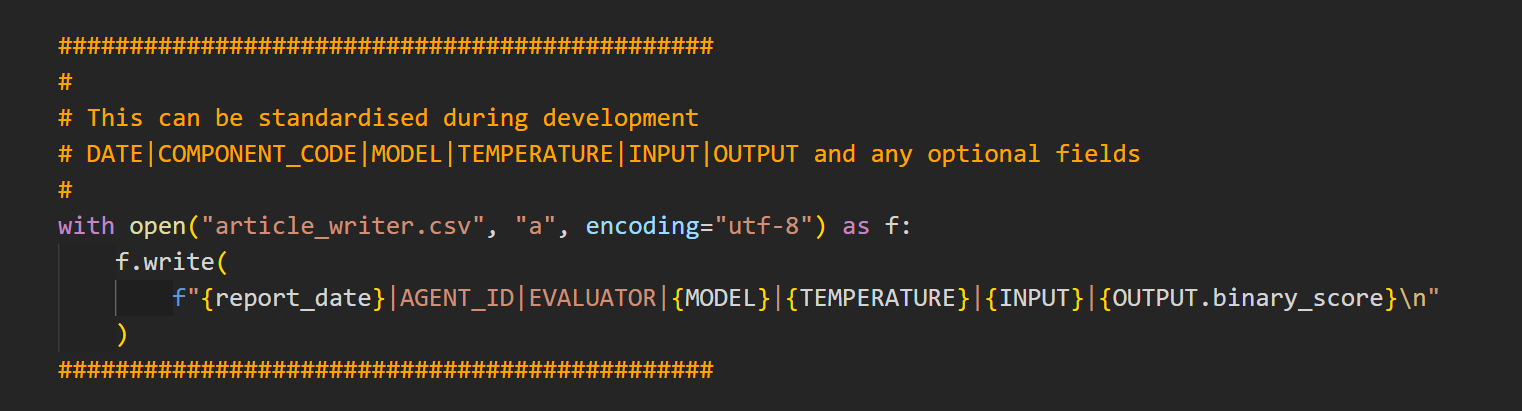
- Use standard export to CSV at each LLM point so that each 'agent' is self-reflecting.
Agents/tools are (mathematically) a function with:
- input
- output
- retrieval/memory/tools (optionally)
- metadata (model, temperature, etc.)
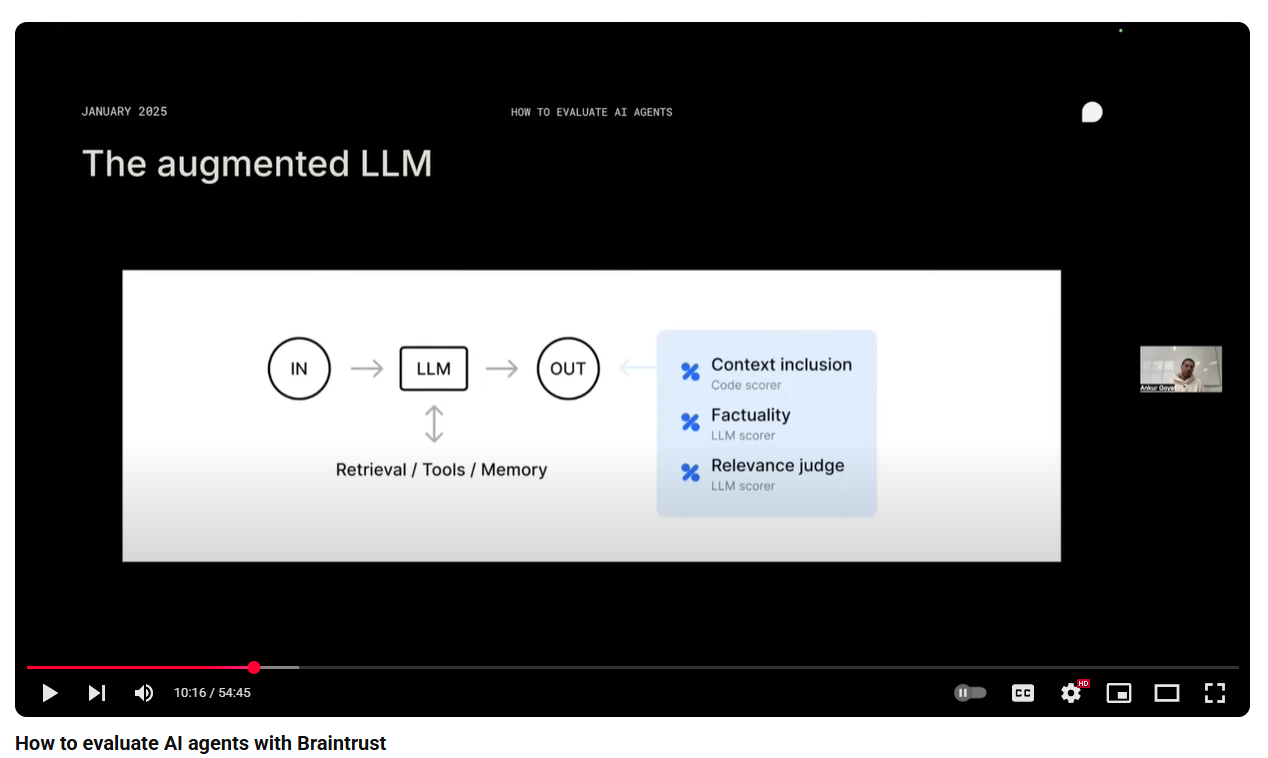
Each Agent has its own self-reflection by exporting the above to a CSV.
This CSV can then be analysed using a range of Eval Libraries like Evidently, DeepEval and Ragas, with or without references (ground truths).
We can have two traces at each point. One a more concise version for the developer (and QA) as well as a complete trace for the QA.
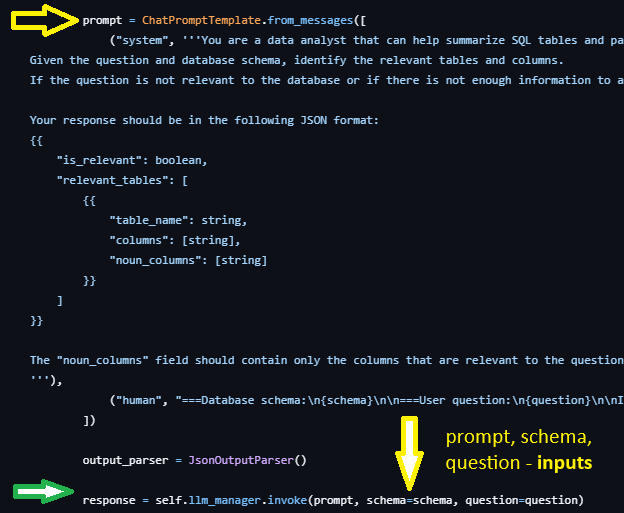
We find where the LLM point is in our code if we are doing evals after dev:
Evaluation¶
Add REFERENCE column to dataset and then do evals.
Once we have our output dataset, we can add ground truths/references and then carry out evals using a range of libraries like Evidently.ai, (my favourite), RAGAS, DeepEval etc.
We can also create our own evals.
The log files are generated in real time enabling not just evaluation but also real time monitoring.
I have also found the log files very useful during development work and bug-fixing.
This way of Evaluation Driven Development creates better understanding and development of LLM apps and focuses attention on 'why, what and how' of our agent.
A/B Testing¶
We can have multiple versions of the same Agent running in parallel and then do A/B testing on them. This may just be changing the prompt so that we can find the best performing prompt for the Agent, or it may be changing the model used.
Cost Optimisation¶
In production, we can obtain the number of input and output tokens used. We can calculate the cost. We can then compare costs for different models that still give comparable performance.
In this way, we are monitoring and reducing costs through real time evalustions.
Advantages¶
Decouples app code and evaluation code. We can move a 'node' from one place to another without having to change the code in the app.
Portable Agent/Eval combinations.
Evals are real time and support both developer and QA.
Clients can have a window on their Agents and have a greater sense of trust and understanding as they hand over their business to Agents.
Frictionless integration to existing apps and new ones.
CSV output easier to digest than UI traces. In fact, I tend to want to export the traces as CSVs.
If we are using some sort of Agent Context Protocol, we can avoid mixed telemetry systems by having each agent do its own telemetry.