Key Ideas¶
In their rawest form, AI Agents have the following structure:
model = "gpt-3.5-turbo" # Model
model_endpoint = "https://api.openai.com/v1/chat/completions" # just one endpoint
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
# payload may vary from LLM Organisation but it is a text string.
payload = {
"model": model,
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
"stream": False,
"temperature": temperature,
}
# Use HTTP POST method
response = requests.post(
url=model_endpoint, # The endpoint we are sending the request to. Low Temperature:
headers=headers, # Headers for authentication etc
data=json.dumps(payload) # Inputs, Context, Instructuins
).json()
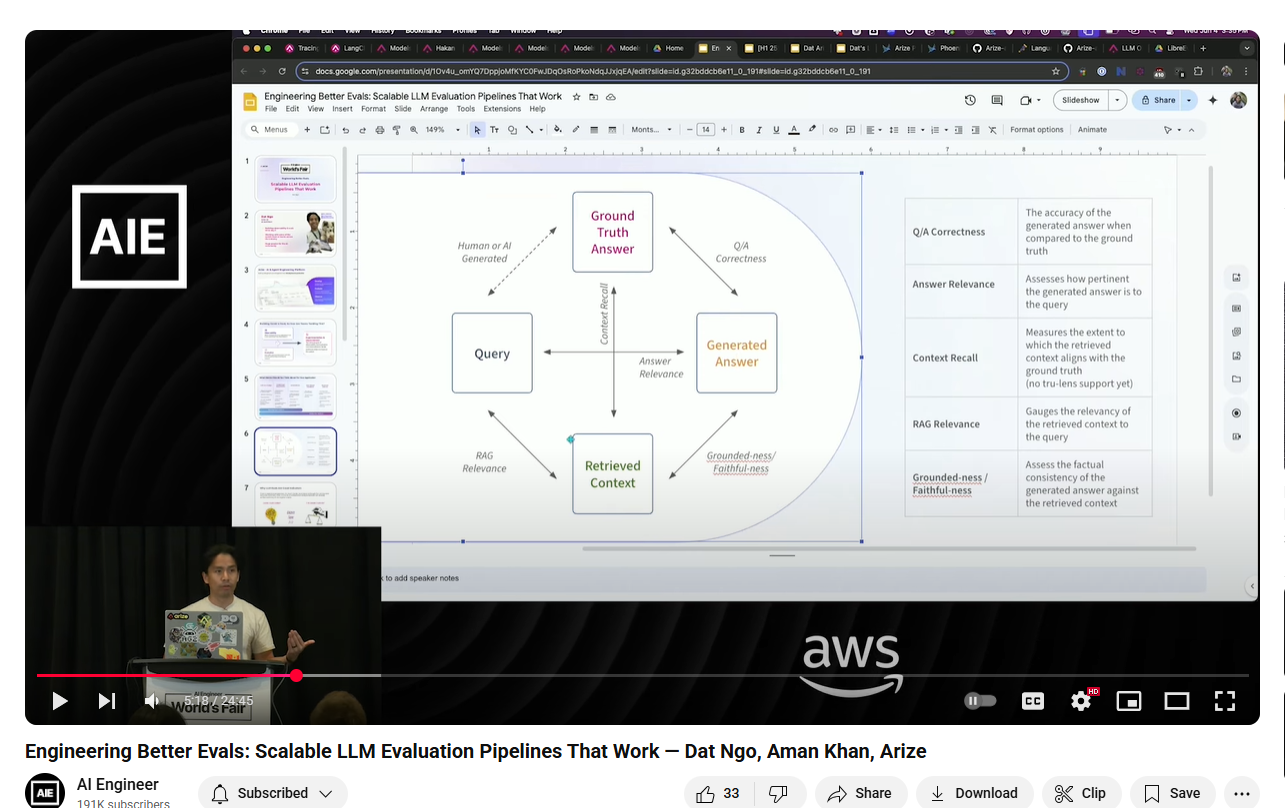
We can therefore log INPUTS and OUTPUTS as needed with the response containing a wealth of information.
This gives us full observability - in fact the maximum possible - and we can then proceed to EVALS.
-
LLM evals ≠ benchmarking.
-
LLM evals are a tool, not a task.
-
LLM evals ≠ software testing.
-
Manual + automated evals.
-
Use reference-based and reference-free evals.
-
Think in datasets, not unit tests.
-
LLM-as-a-judge is a key method. LLM judges scale rather than replace human evals.
-
Use custom criteria, not generic metrics.
-
Start with analytics.
-
Evaluation is a moat.
The reason why an LLM judge gives label helps teams know what to fix...
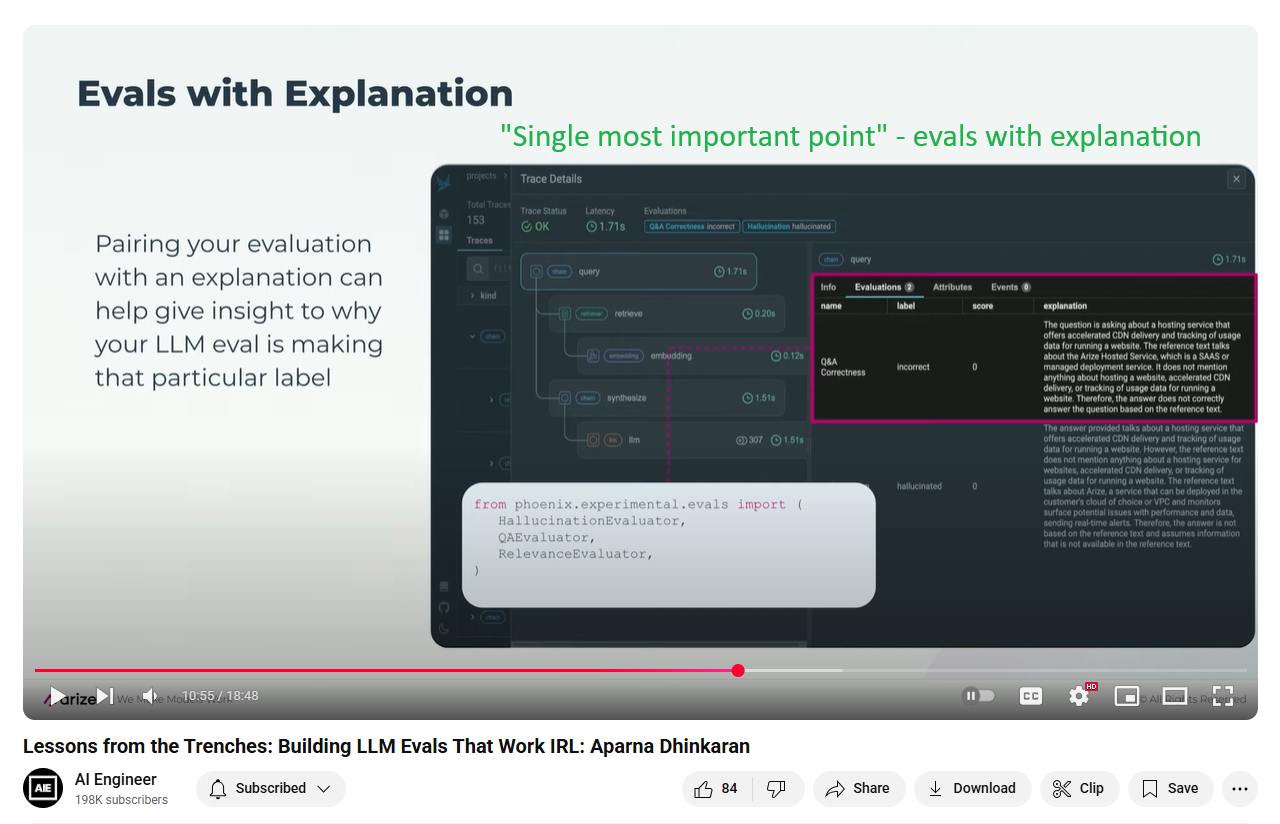
We avoid numeric scores but use categorical labels. What does a 7 mean? LLM judges can have different scoring systems.
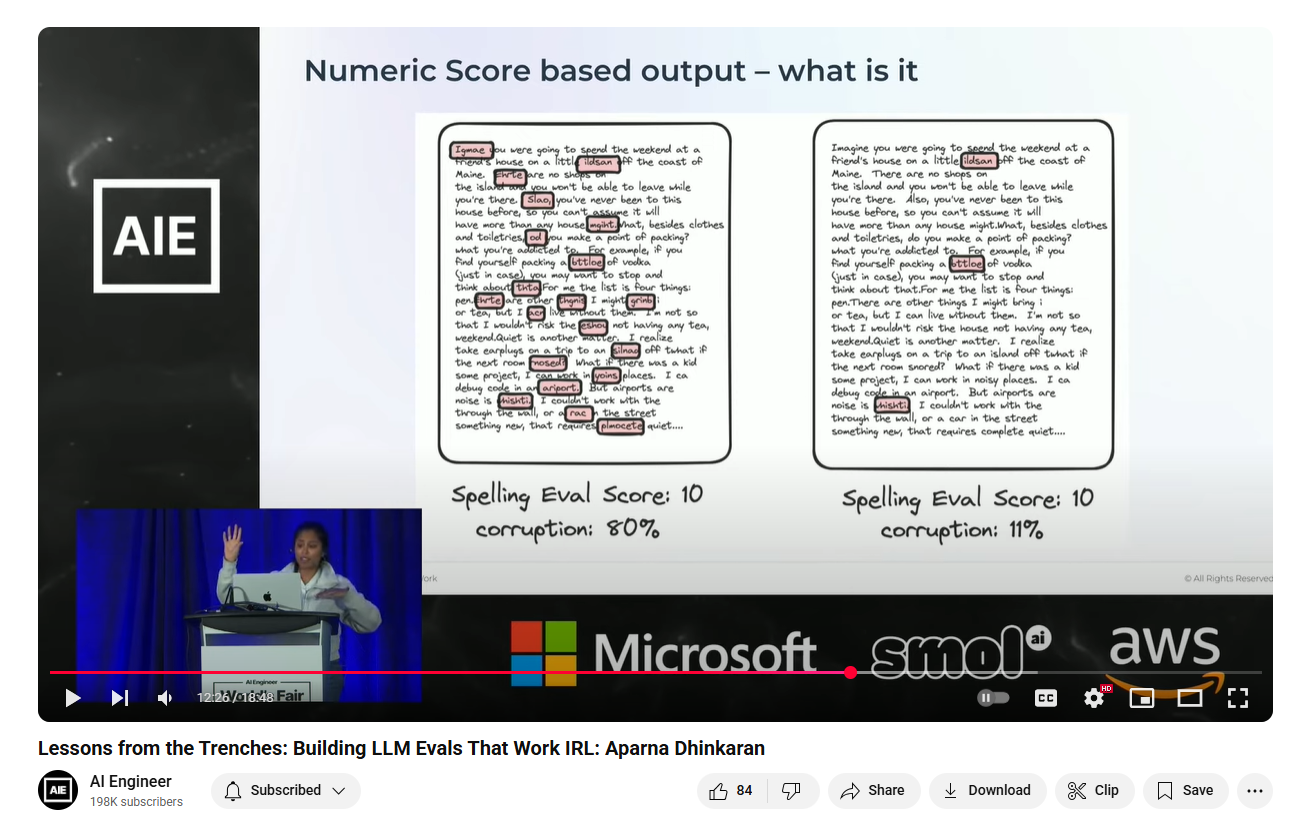
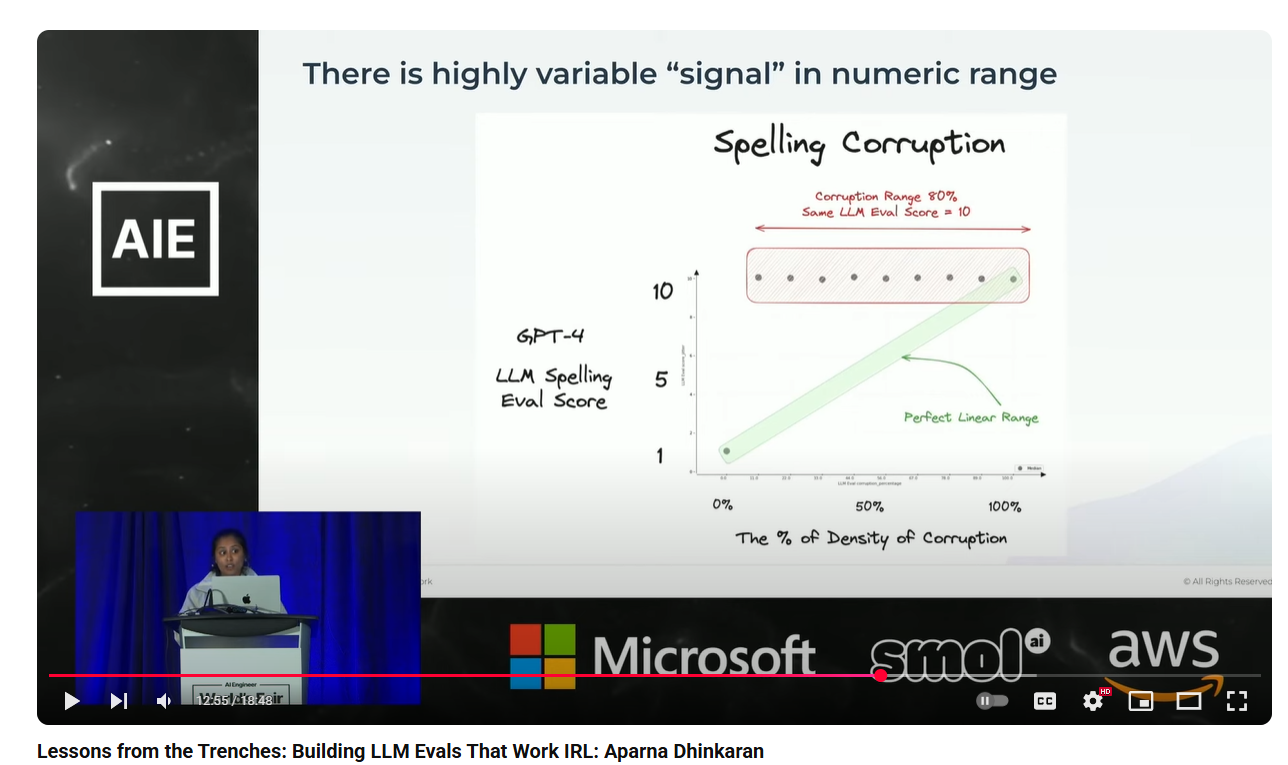
This research showed that LLMs give 1 or 10 not a linear scale.
LLM evalas are part of a bigger testing programme.
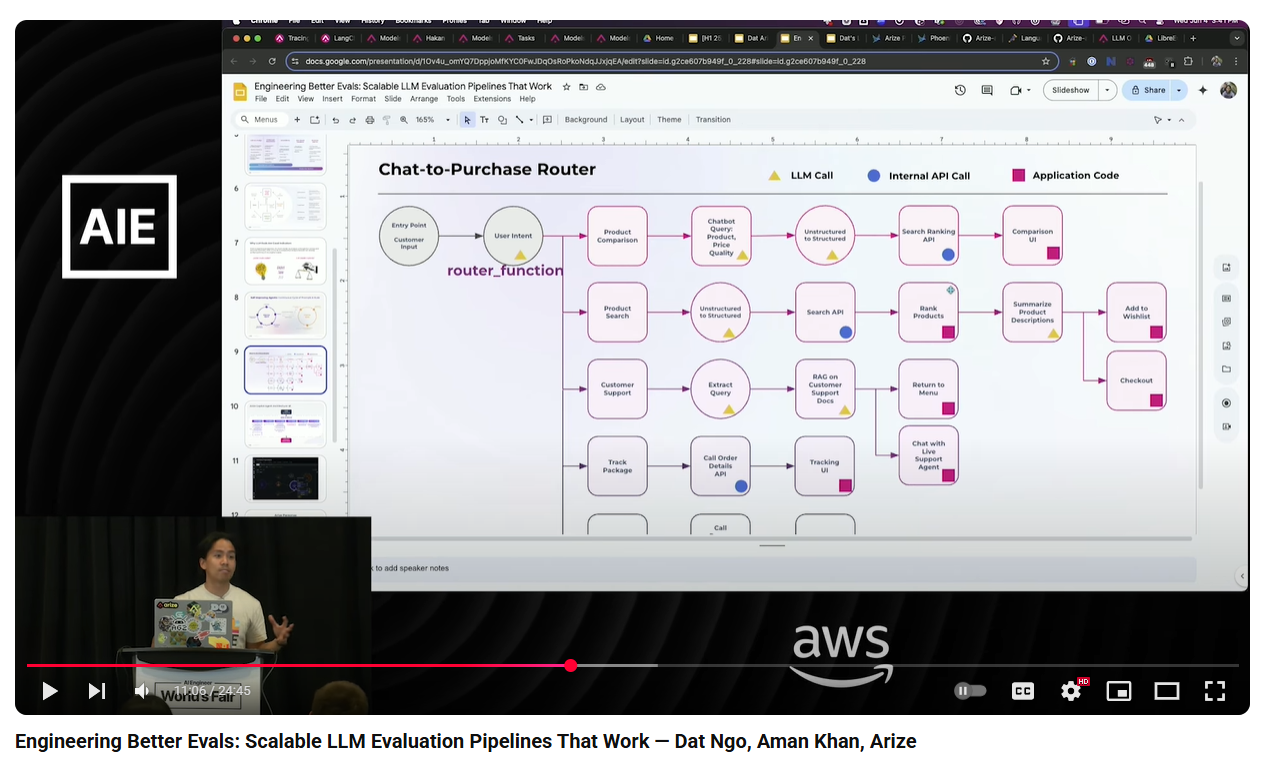
Not all evals are LLM based - traditional code based evals are also useful and in some ways better.
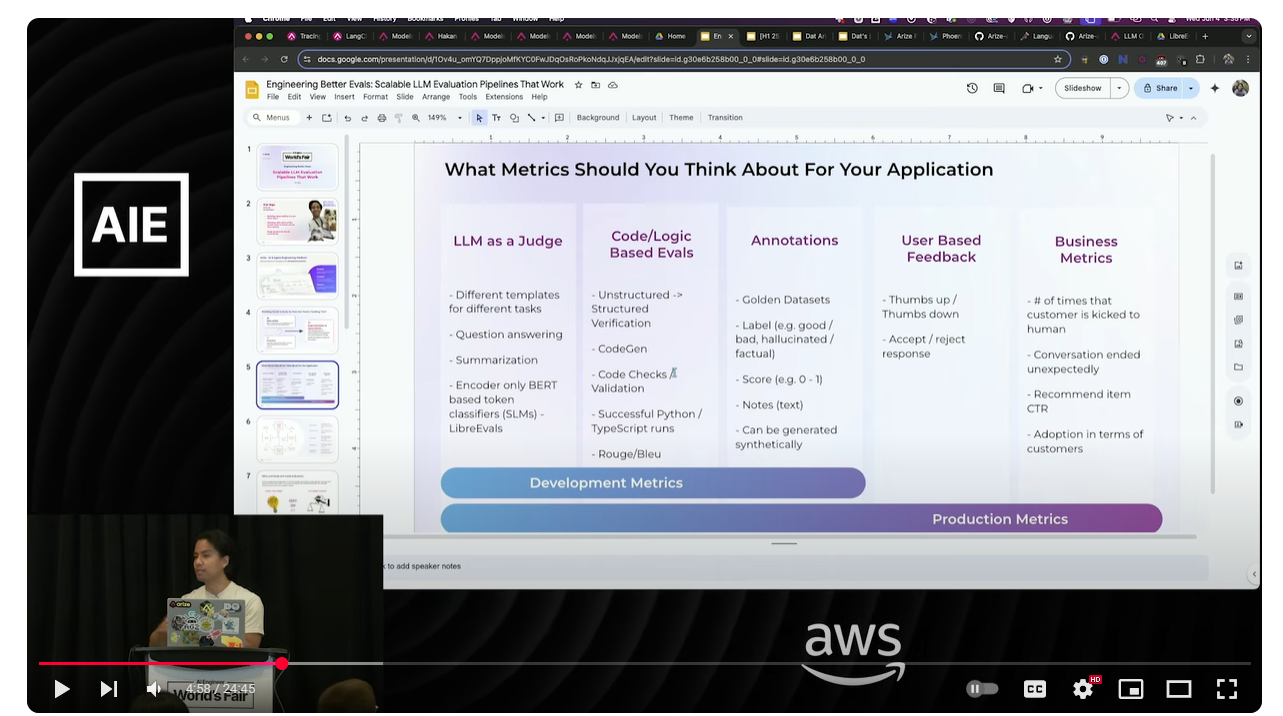
We can have a matrix of evaluations in one component.