LLM as Judge¶
LLM Judges are for scaling not for total replacement of Human Evaluators. They will ulimately need to be evaluated by a human.
LLM Judges¶
The technique of an (untested) LLM generating question/answer pairs to act as ground truths to then test an LLM seems illogical but current thinking states this is quite effective.
This technique might be used by developers to improve the knowledge system as they work on it rather than getting human evaluations at every step.
Smaller, fine-tuned models maay be more effective that larger models and if we use Open Source models we need only pay for compute.
Arxiv Paper: https://arxiv.org/pdf/2412.05579
Definitive guide to building LLM Judges

What has been found to be most effective is to not get an LLM Judge to come up with its own answer and then see if this is 'equal' to the answer of the agent. There is something ungrounded in the logic present with this, an untested technique testing an agent.
It is better to have the LLM Judge give an answer and reason as to whether given the query and output of the agent is 'good'.
What is 'good'? What is a 'good email' if we are asking our judge to evaluate emails produced by the agent.
This is where a number of examples of both 'good' and 'bad' emails are given in the prompt to the judge or in its fine-tuned prompt.
Building effective judges is a skill in its own right and will need testing, evaluation and monitoring in its own right.
Example prompt¶
prompt = f"""You are an expert evaluator tasked with judging the conciseness of text responses. Your job is to assess whether a given response effectively communicates the necessary information without unnecessary verbosity or redundancy.
EVALUATION CRITERIA:
Rate the response on a scale of 1-5 for conciseness:
- 5 (Excellent): Perfectly concise - communicates all necessary information with no wasted words
- 4 (Good): Mostly concise with minimal unnecessary content
- 3 (Average): Reasonably concise but could be tightened up
- 2 (Poor): Somewhat verbose with noticeable redundancy or filler
- 1 (Very Poor): Extremely verbose, repetitive, or filled with irrelevant information
INSTRUCTIONS:
1. Read the provided response carefully
2. Identify the core message and essential information
3. Look for redundancy, unnecessary elaboration, or filler content
4. Consider if the same information could be communicated more efficiently
5. Assign a score from 1-5 based on the criteria above
6. Provide a brief explanation for your score
OUTPUT FORMAT:
CONCISENESS SCORE: [1-5]
REASONING: [2-3 sentence explanation of why you gave this score, highlighting specific strengths or areas for improvement]
SUGGESTED IMPROVEMENT: [Optional - if score is 3 or below, suggest how the response could be made more concise]
RESPONSE TO EVALUATE:
"{response_text}"
Uses¶
Some example additional uses:
- Politeness: Is the response respectful and considerate?
- Bias: Does the response show prejudice towards a particular group?
- Tone: Is the tone formal, friendly, or conversational?
- Sentiment: is the emotion expressed in the text positive, negative or neutral?
- Hallucinations: Does this response stick to the provided context?
- Adversarial: We can test it does NOT do things as well as test edge cases.
By asking for not just the grade but its reasoning, we can get a more complete picture of how the judge is evaluating the LLM.
Code demo:
Examples
https://www.youtube.com/watch?v=LZJTrAXcyFM
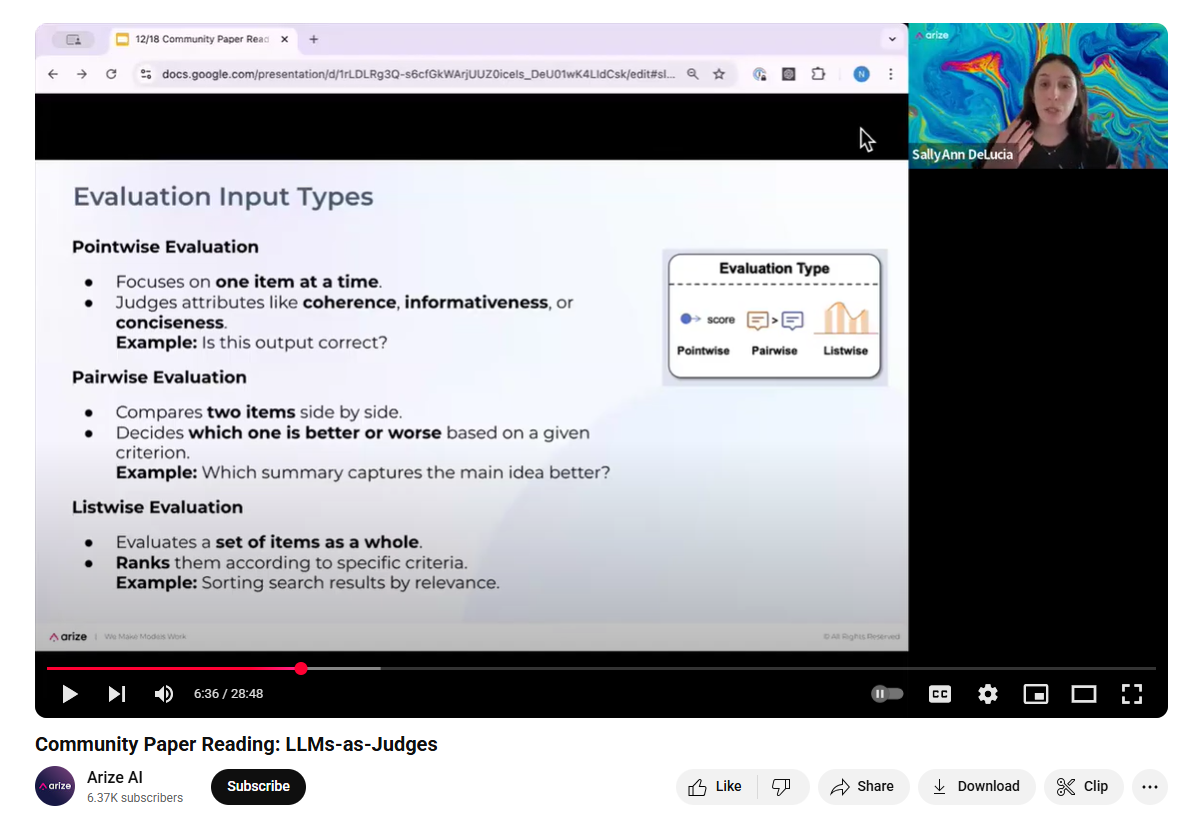
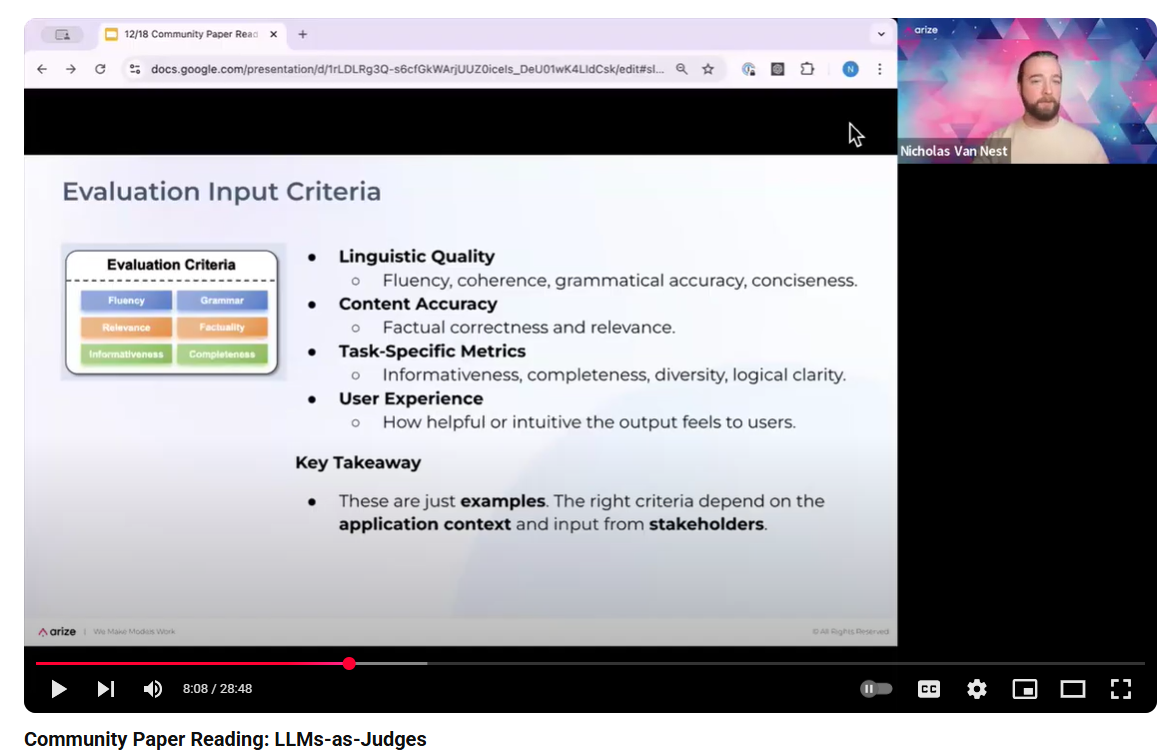
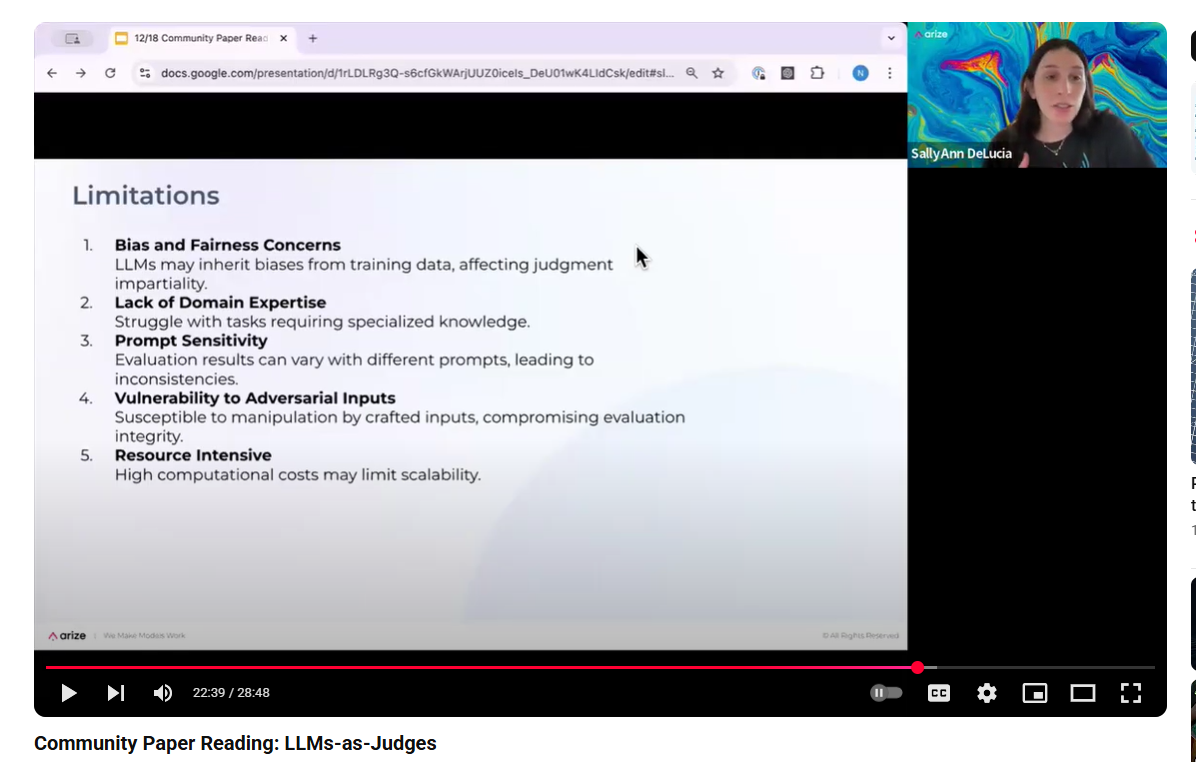
Testing the Judge¶
If we have a Golden Dataset, we can run the judge over it and see how it compares to our domain exppert.
Periodic re-evaluation will be needed.
Create Judge¶
There is a comprehensive article on the process of creating LLM as Judge https://hamel.dev/blog/posts/llm-judge/.
Creating a specialist LLM can be done in many ways:
- In-Context Learning
- Supervised Fine Tuning
- Direct Preference Optimization
- Merging LLMs
- Distillation
Just like our app LLM, we will need to evaluate and monitor them.
For example, InstructLab from IBM, enables us to fine tune a small open source model with domain knowledge.
Using 5-10 sample questions and a store of data, an md file, InstructLab will then generate 100s of synthetic data QnA pairs based on the sample questions and the data provided.
It has algorithms to check for hallucinations but a Human In The Loop, (HITL), is still needed to check the data.
These small, open source models, can then be used as specialist LLM Judges.
https://github.com/instructlab