Case Study 1¶
All code for case studies are here: https://github.com/Python-Test-Engineer/llm-evaluation-framework
Whilst this case study uses Langgraph, the framework is not of importance.
Patterns of routing, recursion and decision making that are present in this app are generic patterns and this app could itself be a a sub-app for another app.
The principles and techniques used to evalauate AI Agents and LLMs is the core matter here.
Business ROI¶
This business is about writing articles/blog posts in many different languages.
It must be:
- About AI
- In the chosen language
- Around a certain specified length
- Not be sensational but very professional and factual
The business depends on its performance and reputation.
We must ensure these outcomes are met as failure to do so will jeopardise the business and its profits.
Effectively, the ROI is to be protected at the very minimum and with articles produced in accordance with the business model, the better these criteria are met, the better the business and ROI.
It is more than just working correctly.
Our evaluations must reflect this.
Article Writer App¶
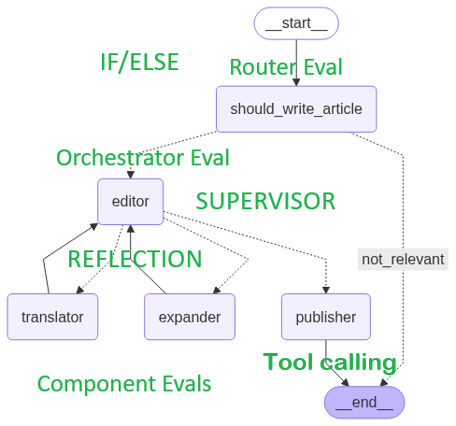
Given a title for an article, the app determines of the artcle title is about AI.
If not it goes to the END.
If it is, it gets passed to an editor that does three things:
- Translates to a configured language, French in this case.
- Expands the length of the article title to content of more than N words with N specified in config.
- Makes a subjective evaluation that the article IS_NOT_SENSATIONAL.
If all three are YES, it then set the spostability flag to YES and moves to the publisher node where certain actions are taken if yes.
If the postability is still no after the MAX_RETRIES, then it too moves to publisher but the no value will cause the article not to be published.
In the app, the publisher node has no code but there is no agentic action in this node and it is deterministic.
This is a leaf level sub graph meaning it is at the end of all the Agentic actions.
This could be a sub-graph that is part of a larger graph. We would then test each sub-graph separately.
The first node should_write_article determines if the short article headline is about the selected content topic, in our case AI/Technology.
If so, it goes to the editor that ensures:
- It is translated into the chosen language, French in this case.
- Has sufficient length.
- Is not sensational.
It the above three are 'yes' then the postability flag is set to 'yes' and
it goes to the publisher for pricing where we see the use of tracing tool calls, particulalry those that are dependent on each other.

In publishing, we use a prompt to determine the price of the article either by using a random function or a subjective valuation. Then another tool uses the price to give it a rating for cost-effectiveness.
publisher_system = f"""As a publisher you determine the price of the article and also rate its cost-effectiveness.
PRICING STRATEGY:
{pricing_instruction}
After getting the tool result, you can make final adjustments but must stay within 10-90 GBP range.
Rate the cost-effectiveness as:
- VERY_GOOD_VALUE: 10-40 GBP (excellent value for money)
- GOOD_VALUE: 41-70 GBP (reasonable pricing)
- EXPENSIVE: 71-90 GBP (premium pricing)
Then use the rate_article_price() tool to get the official rating for your chosen price.
Provide your final pricing decision with justification explaining:
1. Which tool you used and why
2. Any adjustments you made to the tool result
3. How the final price reflects the article's value
Available tools:
- get_article_price_randomly(): Returns random price 10-90 GBP
- get_article_price_based_on_word_count(): Returns price based on word count logic
- rate_article_price(price): Returns rating for a given price"""

Of course, the exact nature of the output can be changed to suit but this shows what tools were used.
We have a MAX iterations and if the postability is not yes after MAX iterations then we move still move to publisher but the code will detect no and move to __END__ without taking yes actions.
This case study shows how we can evaluate ROUTING and also parallel tool call - we can think of a node as a tool call as everything is just a function.
We can log all the output into the CSV file so that we can see more detail about the LLM call like tokens etc. or filter before dumping to log file.
We can log input_tokens and output_tokens so that we can evaluate cost.
In EVALS01 and EVALS04 which use structured output, we use tiktoken library to get token counts. In the other EVALS where we ar enot using structured output, the metadata containing this information is more readily available.
Client Requirements¶
We are charged with testing and monitoring this agent.
What might we need to determine?
- Does the app as a whole produce the right final output? Language, length, not sensational?
- If the
postabilityisyesare the other flags allyes- this is app logic? - What is the latency (time) for each LLM call?
- Can we judge the quality of the article using an LLM Judge and how is this LLM Judge created?
- What impact does the choice of model have on cost, latency and performance? Can a compromise on quality yield siginificant cost savings without increasing latency significantly?
- Do each of the nodes work correctly?
This can provide both technical and business effectiveness evaluation - in production, in real time and in front of the client.
Dataset¶
I generated 30 sets of inputs and outputs and added 'domain expert ground truths' to them.
I then ran the inputs throught he app, got the evaluations trace CSVs and the evaluated our app.
There are 4 evaluations, one for each of the four output files.
Evals¶
There is a folder case_study1/langraph/evaluations/results that has Notebooks doing the evaluations.
EVALS01¶
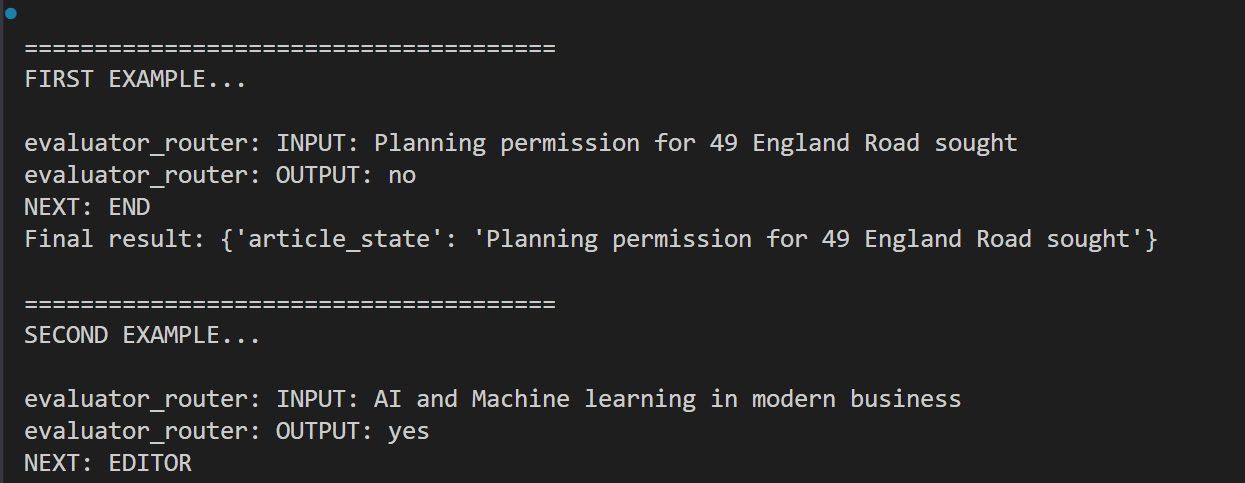
Test: Ensure only AI articles are processed by having 'yes' in the output of the router.
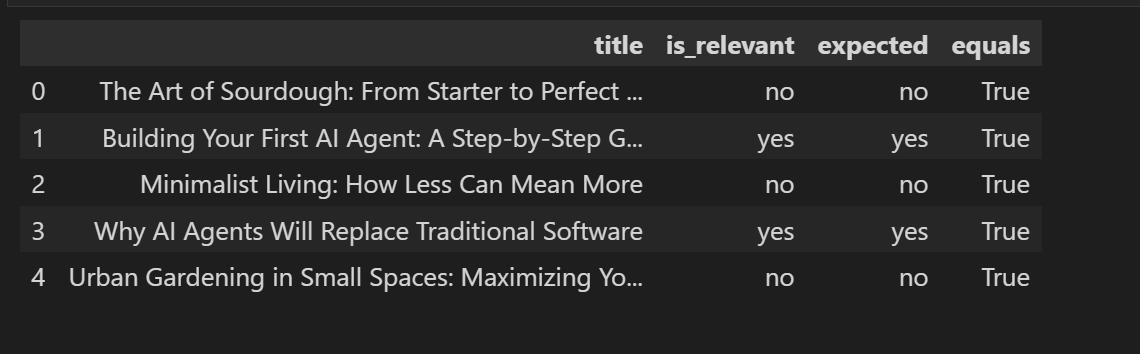
We can include our own domain expert classification and create analytics.
We may also ask LLM to give its reasoning because in edge case's we might accept its contradictory classification.
We can scale up using LLM as a Judge...more on this later.
As useful as this is, we can do better.
If we ask the LLM to give an explanation for its decision, we can get a better understanding of what the LLM is doing and we may find we have been missing the mark. If we understand its reasoning better, we can improve our logic or discount the failure.
This is one of the 'pro-tips' industry experts give.
EVALS02¶
Test: Ensure title is translated to correct language - French
We can use NLP rather than an LLM to save on costs.
EVALS03¶
Test: Ensure article has correct number of words - CONENT_LENGTH - and we can also ensure language is still correct.
This is a deterministic test where we determine the number of words.
EVALS04¶
Test: Ensure if the can_be_posted is yes then the other flags are also yes - is_not_sensational, is_in_correct_langage and meets_word_count.
This is a deterministic test of logic.

EVALS05¶
The PUBLISHER node use two possible tools to determin the price and then another tool to rate that price for cost effectiveness. These are two dependent tool calls.
We can see and edited ouput of the tools and arguments called:
However, we may want to evaluate whether it is a 'good' article. This raises the question of what do we mean by 'good'.
Looking at the data, our human evaluators will be able to see what features exist in articles they determine to be 'good'.
This will enable us to refine the prompt in the app to produce a 'good' article and also develop the prompt for the LLM as a Judge. This is expanded here https://evaluating-ai-agents.com/evaluation/llm_judge/.