Evaluating AI Agents¶
Craig West - https://craig-west.netlify.app/
Code repo: https://github.com/Python-Test-Engineer/eval-framework
- In production
- In real time
- In front of the client
optimising performance, cost and latency - ROI!
Imagine a company builds some AI Agents for your business, Agents that are not wholly deterministic.
You trust your business to this app developed by the company and PAY for it.
What would create TRUST and CONFIDENCE for you in those Agents?
How could the company demonstrate to you reliability, capability and ROI?
This is why we do EVALS.
Aim¶
This is a practical manual with articles and framework repo to establish a fricitonless way of testing and evaluating Agentic systems both for the developer and QA.
- No vendor lock in - tracing is done by logging to CSVs in development and production
- Standard Python
- Build self-evaluation into your Agents for portability
- Evaluation Driven Agent Design principles
- Use of LLMs as Judges, creating fine-tuned models where needed
Error Analysis First¶
The first step is to see where our agents are failing.
This gives us focus and an ROI apporach to evaluations.
From our error analysis, we can then build our evals and test them.
Core Metrics¶
How will we know EVALS have been worth it?
Set business success criteria and ROI.
Evaluate to measure increase in success and consequent ROI.
Do sales go up or down with/without EVALS?
Case Studies¶
In Case Studies, we look at a range of apps and implement evals using essentially logging to a CSV which we can then test, evaluate and monitor.
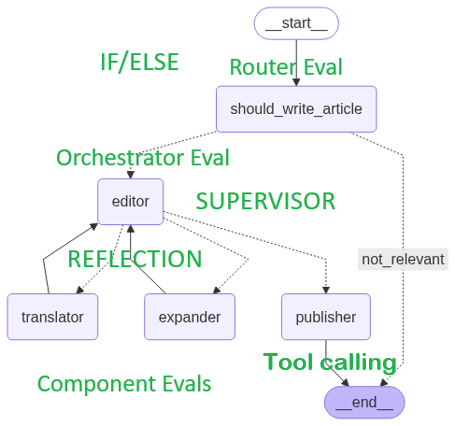
The feature Case Study is Case Study 1 that is an app, (LangGraph), that uses ROUTING, REFLECTION, TOOL CALLING and DECISION MAKING - most of the standard patterns we see in apps, followed by some notebooks that carry out the evals.
There are two parts:
-
Observability getting data on what the LLM call used as inputs, context and outputs along with any metadata.
-
Evaluation - did the LLM call work as expected and if not how did it go wrong? Was the trajectory and workflow maintained as coded?
We can think of Agents as (mathematically) a function with:
- input from client
- context: retrieved data from stores, tools and memeory(optionally)
- output
- metadata (session_id, stack,model, temperature, etc.)
with metadata of session_id, stack, model, temperature, etc.
We have access to these data points and we can log them to a CSV.
https://www.usebraintrust.com/
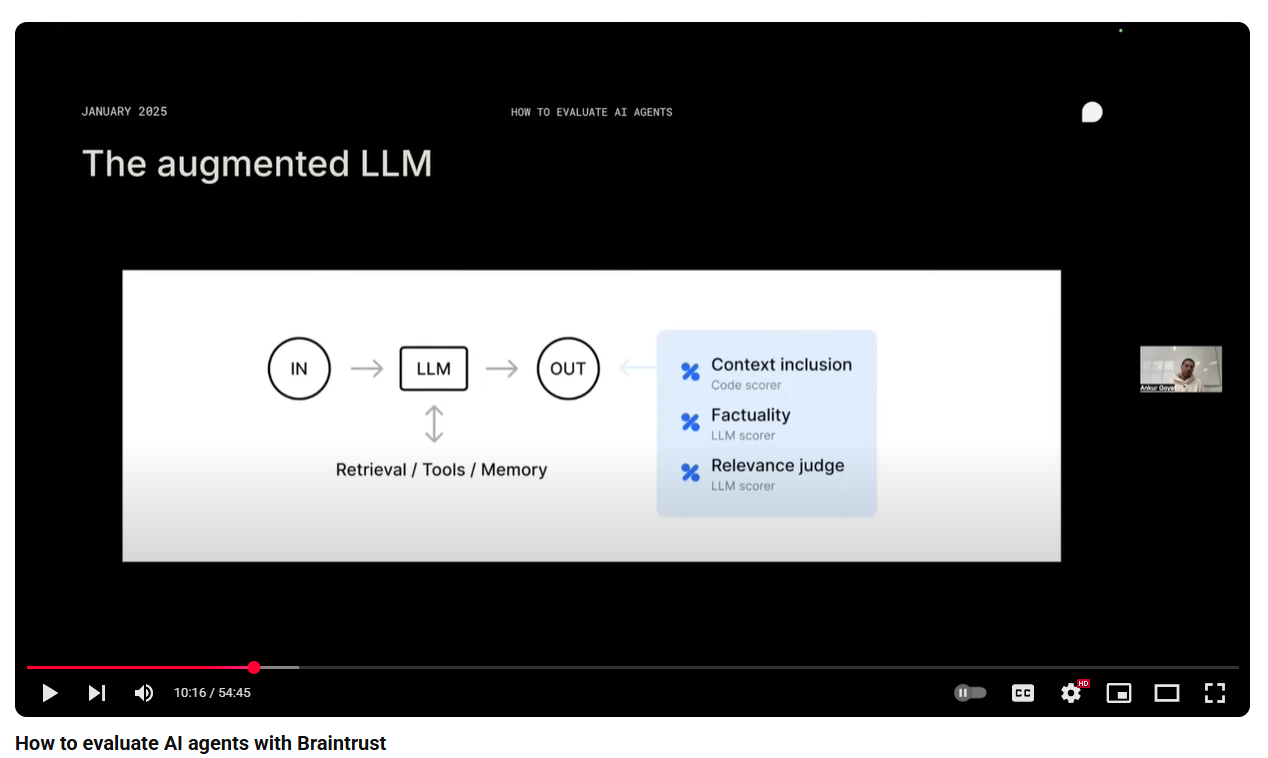
Observability¶
Logging out this data to a CSV then allows us to work with it as we please.
In real time production, we can sample to monitor latency, effectiveness and cost.
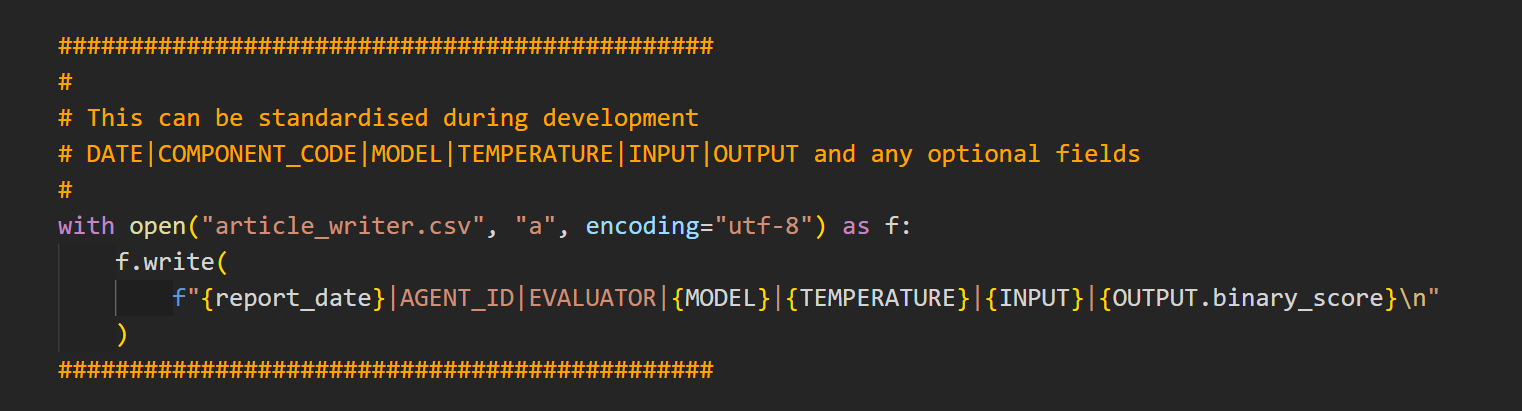
(In reality, we will have session/run id so that we can link up traces across evals).

If we want to add evals after the app is created, we find the LLM call and then add our logging code.
This is from Case Study 4 which is Langchain's full stack SQL agent:
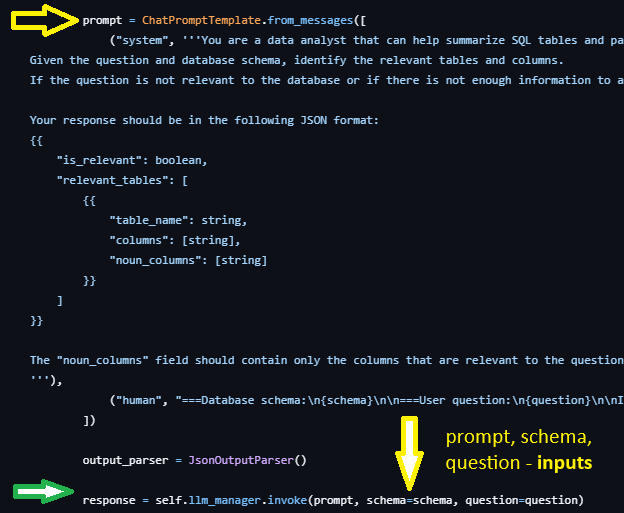
For my videod talk at BrightonPy Feb 2025 and repo about 'Creating AI Agents from Scratch' see https://github.com/Python-Test-Engineer/btnpy. This will show you how to create a simple Agent from scratch and you will see that creating observavility through logging to CSV is standard Python.
In Case Study 1, we work with a LangGraph app that is modelled on an article creation business.
It has ROUTING, REFLECTION, TOOL CALLING and DECISION MAKING - most of the standard patterns we see in apps.
ROI
- Can we save money by using a cheaper model without affecting quality?
- Can we get more sales by improving it?
- Prevent loss of sales by performance degrading?
- How is it being used by clients and do we need to make any changes?
- What is the latency? Can it be reduced?
- A/B testing of prompts, models and so on.
There are other deterministic tests that an app might require but we do not cover that here - see https://pytest-cookbook.com/ for more on that aspect.
In other case studies, we look at other frameworks to see how we can insert evals into our agents and we also evalutate MCP, RAG and Text2SQL.
Evals¶
A Unit Test in agentic terms is the smallest block of code that uses an llm to determine the ROUTE and the RESPONSE.
It may contain other deterministic functionality which we can test in the usual way, but this manual focusses on testing and monitoring Agentic systems.
Patterns¶
This example neatly uses a number of workflow pattersns - router, orchestrator and worker.
In general:


There is also NEXT - does the Agent select the correct next step where this is applicable?

RAG Output¶
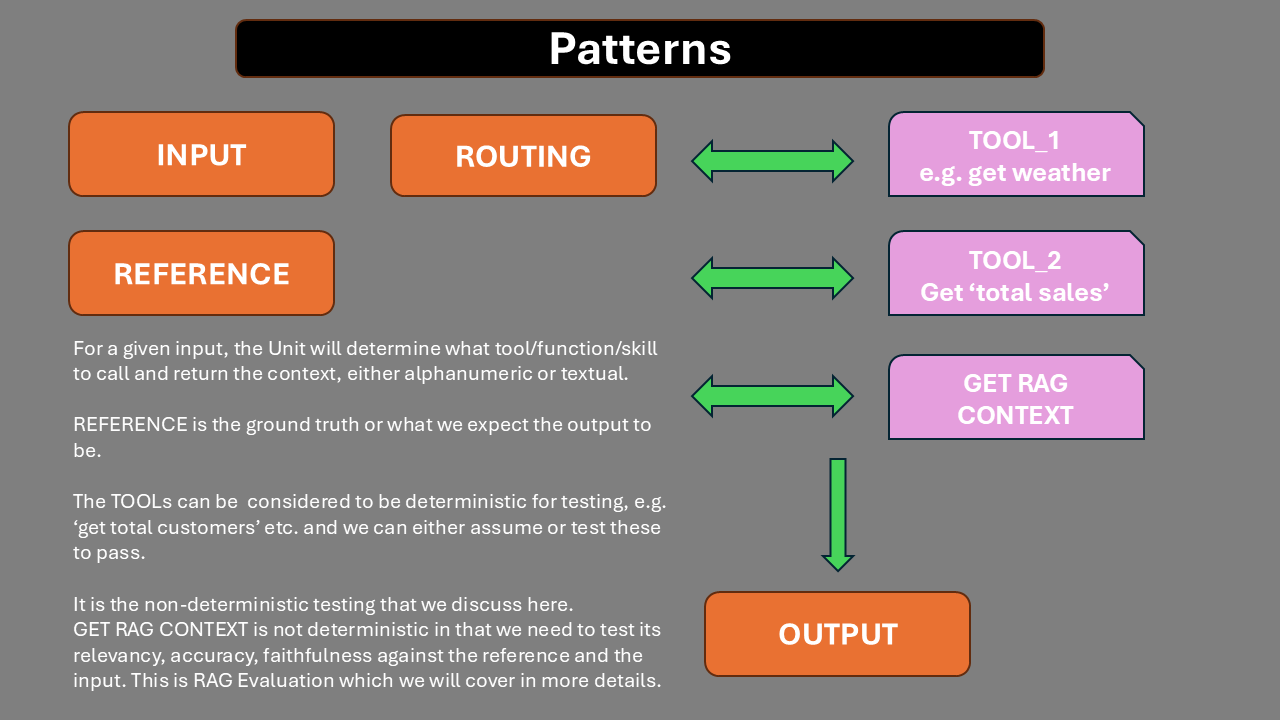
For a given input, we will obtain an output.
We may retrieve additonal context to support the generation of the output.
We will also have REFERENCES - ground truths.
Our goal is to get a number of datasets:
INPUT - OUTPUT - CONTEXT - REFERENCE
and to evaluate tool calling:
TOOL_CALLED - ARGUMENTS - NEXT - EXPECTED
We can do evaluations.
We can also look for OMISSIONS - ADDITIONS - CONTRADICTIONS - COMPLETENESS as alternatives to traditonal F1 scores although these can be computed as well.
Guardrails¶
We can also evaluate system fails as well as doing adversarial testing to challenge the LLM calls.

Frictionless¶
The process needs to be frictionless for developers.
At an accessability talk, the speaker said 'How do you make a blueberry muffin?'.
You put the blueberries in at the beginning and not stuff them in at the end.
This is a sort of Evaluation Driven Development (EDD). We don't need to work out what the evals are before we write the code, we just need to ensure we have observability of all the data we will need in our evals.
We can make each Agent self-observable so that porting an Agent elsewhere still enables us to get observability without having to rewrite surrounding code.
There are many excellent observability and evaluation platforms.
EDD¶
Evaluation Driven Development - creating Agents that have in-built observability customised to what is of importance for latency, reliability and cost -> ROI.
In this manual,we create observability through the use of making Agents/Tools self-g.
We can then we use a range of platform libraries to carry out evaluations in addition to our own custom made evaluations.
In essence, we save on every 'event' - an LLM/Tool call - the information that is necessary for evals and monitoring.
We can therefore do evals and monitoring in production, in real time and in front of the client by enabling client access to a client focused dashboard.
We will see later that as we create effective LLMs as Judge, the effectiveness will rub off on our app.
Our app should be at least as good as the Judge.
What is it we want our Agent to do and how do we know it is doing it?
Code repo¶
All code wired into a PyTest Full Stack framework can be found here:
https://github.com/Python-Test-Engineer/eval-framework
It uses additionally the PyTest Full Stack Framework to provide a fully integrated PyTest Test Suite alongside Agentic Evalauations but does not need knowledge of PyTest to use it - it is an additional feature: